Publicado el 29 mayo 2017
GlusterFS: crea tu almacenamiento distribuido
Vivimos en un mundo donde la información está creciendo de forma impredecible y con ello nuestra necesidad de almacenar estos datos de un modo eficiente. Los sistemas de almacenamiento distribuido, donde los datos se guardan en varios servidores a modo de nodo, ofrecen muchas ventajas sobre los sistemas de almacenamiento centralizados. Rapidez, escalabilidad y Alta Disponibilidad son algunas de las ventajas de estos sistemas de almacenamiento y, como veremos a continuación, su implementación no tiene por qué ser costosa.
¿Qué es GlusterFS?
GlusterFS es un sistema de archivos en red escalable y distribuído, definido para ser utilizado en el espacio de usuario, es decir, sin utilizar el espacio de almacenamiento crítico del sistema, y de esta forma no compromete el rendimiento. Se utiliza en multitud de entornos, como en análisis de datos, streaming y otras tareas intensivas de almacenamiento. Lo mejor de todo es que GlusterFS es un software gratuito y Open Source.
Ventajas de GlusterFS
- Simplicidad: Es fácil de utilizar y al ser ejecutado en el espacio de usuario es independiente del núcleo.
- Elasticidad: Se adapta al crecimiento y reduce el tamaño de los datos.
- Escalabilidad: Tiene disponibilidad de Petabytes y más.
- Velocidad: Elimina los metadatos y mejora el rendimiento considerablemente unificando los datos y objetos.
Conceptos de GlusterFS
- Sistema de archivos distribuido: Es un sistema de archivos en el que los datos se distribuyen entre varios nodos y los usuarios pueden tener acceso a estos datos sin conocer la ubicación real de los archivos. El usuario no experimenta la sensación de acceso remoto.
- Brick: Un brick (ladrillo) es básicamente cualquier directorio o partición que será compartido y que está asignado a un volumen.
- Volumen: Un volumen es una colección lógica de Bricks. Las operaciones se basan en los diferentes tipos de volúmenes creados por el usuario.
Tipos de Volúmenes
GlusterFS soporta diferentes tipos de volúmenes adaptándose a los requerimientos. Algunos volúmenes son buenos para escalar el tamaño de almacenamiento, otros para mejorar el rendimiento, y otros para conseguir ambas cosas.
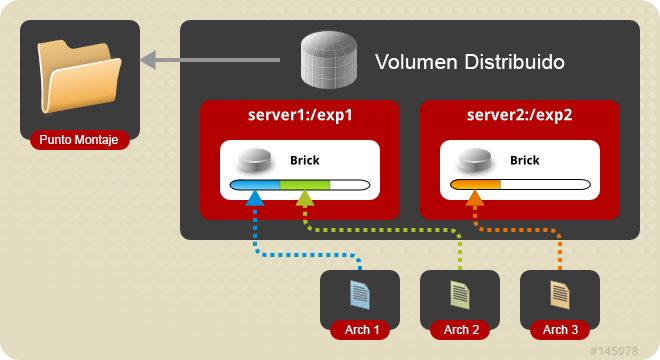
Volumen distribuido: Este es el tipo de volumen por defecto en GlusterFS, si no se especifica un tipo de volumen concreto. Los archivos se distribuyen en varios bricks en el volumen, de forma que el archivo 1 sólo podrá almacenarse en el brick 1 o en el brick 2, pero no en ambos, por lo que no habrá redundancia de datos. Este tipo de volumen distribuido hace que sea más fácil y barato escalar el tamaño del volumen. No obstante, este tipo de volumen, al no proporcionar redundancia, puede sufrir la pérdida de los datos en caso de que uno de los dos bricks falle, por lo que es necesario realizar un backup de los archivos con una aplicación externa a GlusterFS.
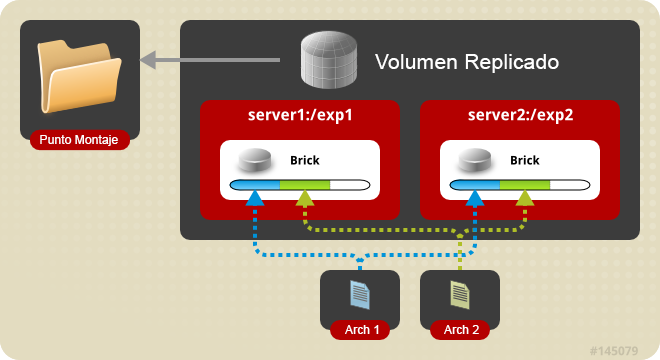
Volumen replicado: Con este tipo de volumen eliminamos el problema ante la pérdida de datos que se experimenta con el volumen distribuido. En el volumen replicado se mantiene una copia exacta de los datos en cada uno de los bricks. El número de réplicas se configura por el usuario al crear el volumen, si queremos dos réplicas necesitaremos al menos dos bricks, si queremos tres réplicas necesitaremos tres bricks, y así sucesivamente. Si un brick está dañado, todavía podremos acceder a los datos mediante otro brick. Este tipo de volumen se utiliza para obtener fiabilidad y redundancia de datos.
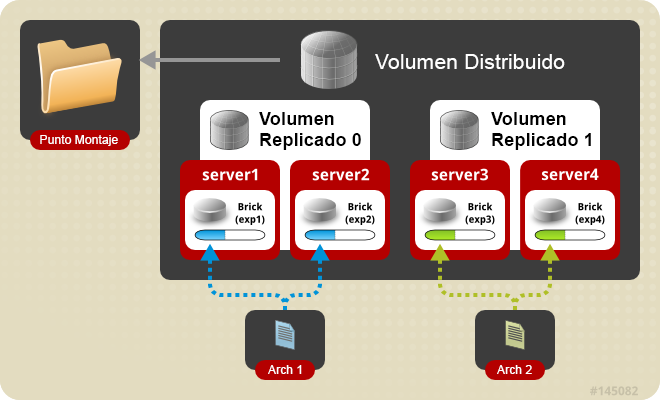
Volumen distribuido replicado: En este tipo de volumen los datos se distribuyen en conjuntos duplicados de bricks. El número de bricks debe ser un múltiplo del número de réplicas. También es importante el orden en que especifiquemos los bricks porque los bricks adyacentes serán réplicas entre ellos. Este tipo de volumen se utiliza cuando se necesita una alta disponibilidad de los datos debido a su redundancia a la escalabilidad del tamaño de almacenamiento. Si tenemos ocho bricks y configuramos una réplica de dos, los dos primeros bricks serán réplicas el uno del otro, y luego los dos siguientes, y así sucesivamente. Esta configuración se denomina 4×2. Si tenemos ocho bricks y configuramos una réplica de cuatro, los cuatro primeros bricks serán réplicas entre ellos y se denominará 2×4.
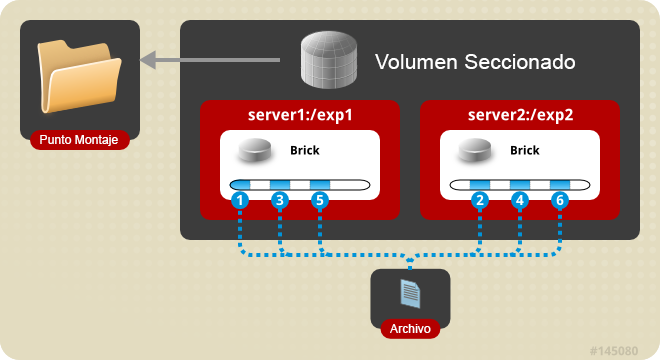
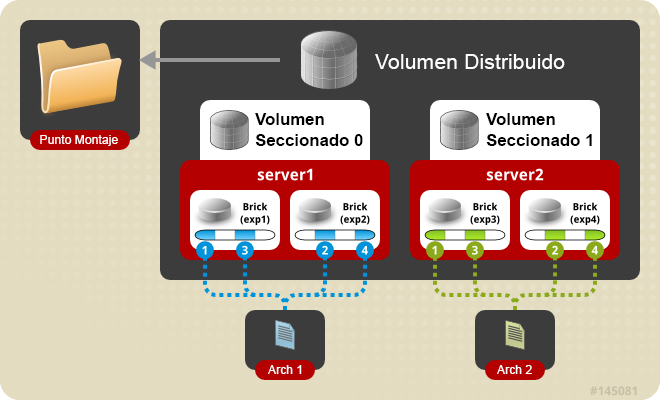
Volumen seccionado (Striped): Imagina un archivo de gran tamaño que se almacena en un brick al que se accede con frecuencia desde muchos clientes al mismo tiempo. Esto provocaría demasiada carga en un solo brick y reduciría considerablemente el rendimiento. En un volumen seccionado los archivos se almacenan en diferentes bricks después de haberse dividido en secciones, de forma que un archivo grande se divide en diferentes secciones y cada sección se almacena en un brick. De este modo se distribuye la carga y el archivo puede ser recuperado más rapidamente, pero en este tipo de volumen perderemos la redundancia de los datos.
Volumen seccionado distribuido: Este volumen es similar al volumen seccionado, excepto que las secciones en este caso pueden ser distribuídas en más cantidad de bricks.
Instalando GlusterFS en CentOS
Vamos a realizar una instalación y configuración de GlusterFS utilizando el modelo de Volumen rReplicado para conseguir una alta disponibilidad de los datos. Este será nuestro entorno de trabajo:
- Dos servidores con CentOS 6.8 instalado en cada uno de ellos (puedes utilizar cualquier otro sistema operativo).
- Los servidores se llamarán en nuestro ejemplo «server1» y «server2».
- Las particiones de almacenamiento en ambos servidores se llamarán «/datos/brick».
1.- Habilitando el repositorio EPEL y el repositorio GlusterFS
Antes de instalar GlusterFS en ambos servidores, debemos habilitar los repositorios EPEL y GlusterFS para satisfacer las dependencias externas. Primero instalaremos EPEL:
# wget http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm # rpm -ivh epel-release-6-8.noarch.rpm
A continuación instalaremos el repositorio GlusterFS:
# wget -P /etc/yum.repos.d http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/glusterfs-epel.repo
2.- Instalando GlusterFS
Instalamos el software en ambos servidores:
# yum install glusterfs-server
Iniciamos el demonio GlusterFS en ambos servidores:
# service glusterd start
Comprobamos el estado del demonio en ambos servidores:
# service glusterd status service glusterd start service glusterd status glusterd.service - LSB: glusterfs server Loaded: loaded (/etc/rc.d/init.d/glusterd) Active: active (running) since Mon, 29 May 2017 06:02:11 -0200; 2s ago Process: 19254 ExecStart=/etc/rc.d/init.d/glusterd start (code=exited, status=0/SUCCESS) CGroup: name=systemd:/system/glusterd.service + 19260 /usr/sbin/glusterd -p /run/glusterd.pid + 19304 /usr/sbin/glusterfsd --xlator-option georep-server.listen-port=24009 -s localhost... + 19309 /usr/sbin/glusterfs -f /var/lib/glusterd/nfs/nfs-server.vol -p /var/lib/glusterd/...
3.- Configuramos SELinux e iptables
Abrimos en ambos servidores el archivo /etc/sysconfig/selinux y cambiamos el campo «SELINUX» a permissive o disabled. Guardamos los cambios y cerramos el archivo.
This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted
Ahora hacemos un flush de iptables en ambos servidores (o bien das acceso entre los servidores en iptables)
# iptables -F
4.- Configuramos el Pool de bricks (Trusted Pool)
En server1 ejecutamos:
# gluster peer probe server2
En server2 ejecutamos:
# gluster peer probe server1
5.- Creamos el volumen GlusterFS
En server1 y server2:
# mkdir /datos/brick/gv0
Creamos un volumen en uno solo de los servidores. Nosotros lo hemos creado en el server1:
# gluster volume create gv0 replica 2 server1:/datos/brick1/gv0 server2:/datos/brick1/gv0 # gluster volume start gv0
Ahora confirmamos el estado del volumen:
# gluster volume info
En el caso de que el volumen no aparezca como iniciado, cualquier error quedará registrado en el archivo «var/log/glusterfs».
6.- Verificando el volumen GlusterFS
Montamos el volumen en un directorio bajo «/mnt»:
# mount -t glusterfs server1:/gv0 /mnt
Ahora podremos crear y editar archivos en el punto de montaje como si únicamente lo hiciésemos en local, y serán replicados en el server2.
Esto es todo. Recuerda que tienes más información sobre GlusterFS en su página web.







En ProxAdmin le ofrecemos servicios de administración de servidores, soporte helpdesk externalizado y servicios IT especializados que le permitirán mantener una presencia en internet consistente y segura.